In action
A real coding agent, no cloud in sight
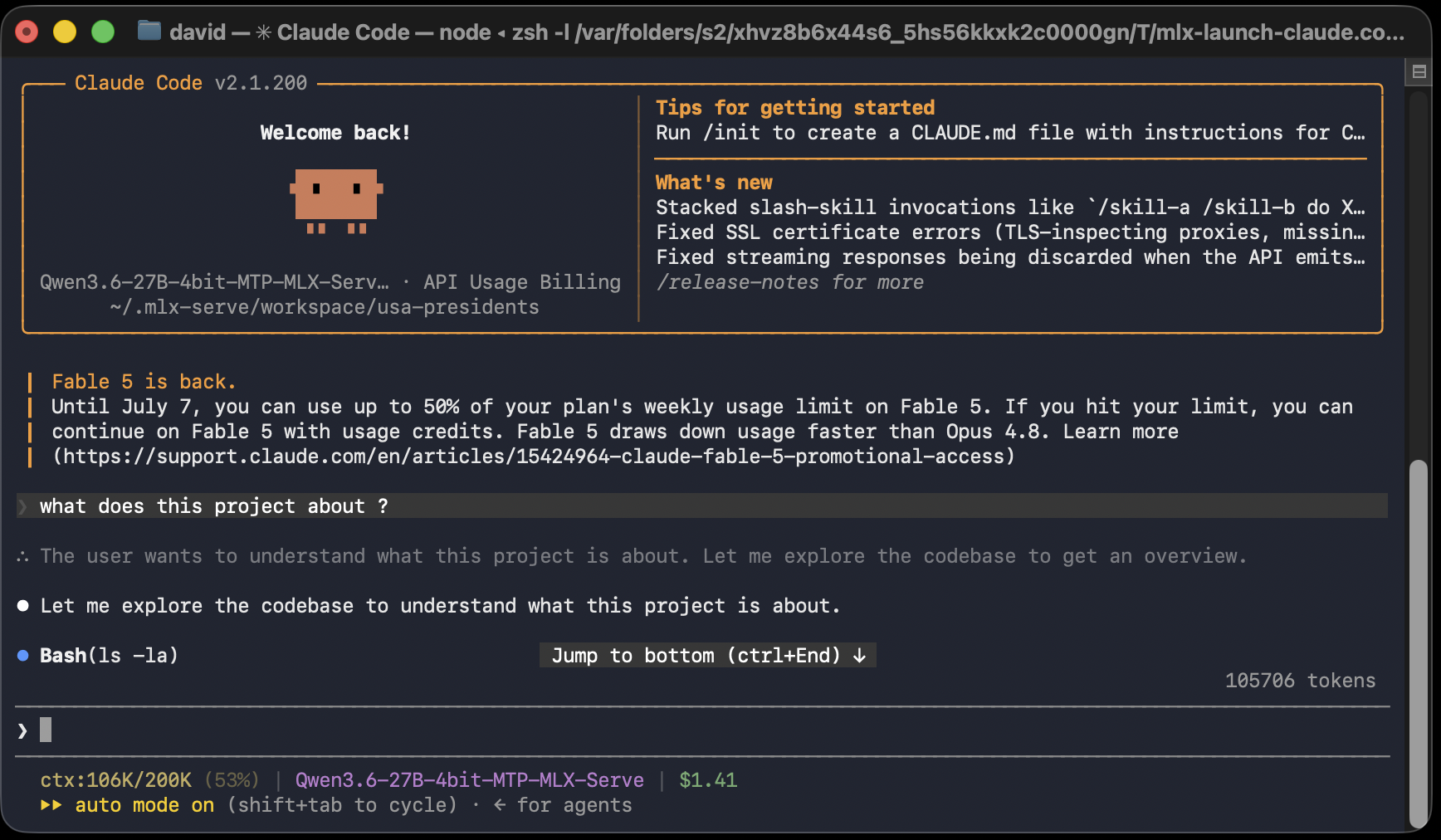
Point Claude Code at a model running on your own Mac. No API key, no per-token bills, no code leaving your machine — one environment variable, or one click in MLX Core.
mlx-serve implements Anthropic's /v1/messages endpoint natively — the same wire protocol Claude Code speaks to the cloud. Change where it points, and everything else just works.
# 1. Install and serve a model (Ollama-style, resumable download) brew tap ddalcu/mlx-serve https://github.com/ddalcu/mlx-serve brew install mlx-serve mlx-serve run qwen3.6:27b # or gemma4 — any MLX or GGUF model # 2. Point Claude Code at your Mac export ANTHROPIC_BASE_URL=http://localhost:11234 claude
Prefer zero terminal? The MLX Core menu-bar app has a one-click Launch Claude Code button: it picks a working folder, wires ANTHROPIC_BASE_URL, dummy API keys, and the default-model variables, and opens Claude Code already connected.
Plenty of servers claim "Anthropic-compatible" and fall over the first time Claude Code streams thinking and tools in the same turn. mlx-serve implements the protocol Claude Code actually uses.
Proper message_start → content_block_start/delta/stop → message_delta sequencing. Every delta references an open block — no "Content block not found" protocol errors mid-stream.
Thinking streams as real thinking_delta blocks with signatures — never leaked into the visible answer, never swallowing it. Reasoning budgets are honored via the thinking field.
tool_use blocks with input_json_delta streaming, and API-layer repair for the JSON small models mangle — Claude Code receives a clean call either way.
Responses report cache_read_input_tokens and reasoning_tokens, so Claude Code sees real prompt-cache savings the same way it does against the cloud API.
Claude Code sends huge system prompts, repeats most of the context every turn, and echoes file content back into edits. That exact shape is what mlx-serve is optimized for.
A Claude Code-sized system prompt (~30 KB) tokenizes in 8 ms — it used to take seconds on every request. A shared-prefix KV cache keeps up to 32 conversation roots warm and survives interleaved subagent traffic, so turn N+1 skips re-prefilling everything it already saw.
Big MCP-laden Claude Code prompts can take minutes of prefill on large models. mlx-serve sends keepalive pings every 5 seconds during prefill so the client never times out — and if Claude Code retries or disconnects, the abandoned request is cancelled within seconds instead of stacking ghost prefills behind each other.
File-edit tool calls echo existing code back with small changes — speculative decoding's best case. With tools active (every Claude Code request), PLD and the Gemma 4 drafter decode edit loops at roughly 2× (72 → 150 tok/s measured on Gemma 4 E4B), with byte-identical output. Qwen 3.6 checkpoints with a native MTP sidecar hit up to 1.8× on agent turns automatically.
generation_config.json instead of raw temp-1.0.~4.3 GB resident at 4-bit, strong tool calling, and the optional assistant drafter for extra code-completion speed. mlx-serve run gemma4.
The sweet spot for agent work. Checkpoints with the trained mtp/ sidecar speculate with the model's own head — up to 1.8× on edit loops, zero setup.
The 284B flagship through the embedded antirez/ds4 engine. Agent mode and tools work on it too.
The embedded llama.cpp engine serves the whole GGUF universe behind the same Anthropic endpoint — pick a file and Claude Code can use it.
Yes. mlx-serve implements Anthropic's /v1/messages endpoint natively — streaming, tool calling, and extended thinking included. Set ANTHROPIC_BASE_URL=http://localhost:11234 and Claude Code talks to your Mac. The MLX Core app's Launch Claude Code button does the wiring for you.
There's no API key and no per-token billing — your Mac does the inference. mlx-serve is MIT-licensed open source, and once a model is downloaded everything works fully offline.
Yes — that exact shape (streaming + thinking + tools in one turn) is hermetically tested against recorded output from every supported model family. Thinking arrives as proper thinking blocks, tool calls stream in valid order, and JSON a small model mangles is repaired at the API layer before Claude Code sees it.
Agent traffic is the best case: warm turns round-trip in ~0.1 s thanks to the prefix cache and an 8 ms tokenizer, keepalives survive multi-minute prefills on 40K-token prompts, and speculative decoding roughly doubles decode on file-edit loops. A 27B-class local model won't match a frontier cloud model's intelligence — but it's yours, it's private, and it's free to run all day.
Yes — the app has one-click launchers for Claude Code, OpenCode, and pi, and anything that speaks the Anthropic or OpenAI wire (Continue, Cursor, the SDKs) can point at the same server.
Download MLX Core, pick a model, click Launch Claude Code. Five minutes from now your prompts never leave your desk again.