Migration
Change one URL. Keep everything else.
Every Ollama-connected tool — Raycast, Obsidian, Enchanted, Open WebUI, ollama-python/js — works against mlx-serve unchanged. The CLI habits carry over too.
Your clients
# wherever a tool asked for your Ollama URL… - http://localhost:11434 + http://localhost:11234 # …that's it. /api/chat, /api/generate, /api/tags, /api/show, # /api/ps, /api/embed, /api/pull all answer natively.
Your terminal
mlx-serve run gemma4 # download + serve + chat REPL, one command mlx-serve pull qwen3.6:27b # resumable, straight from Hugging Face mlx-serve list # what's on disk mlx-serve serve # serve everything, models load on demand
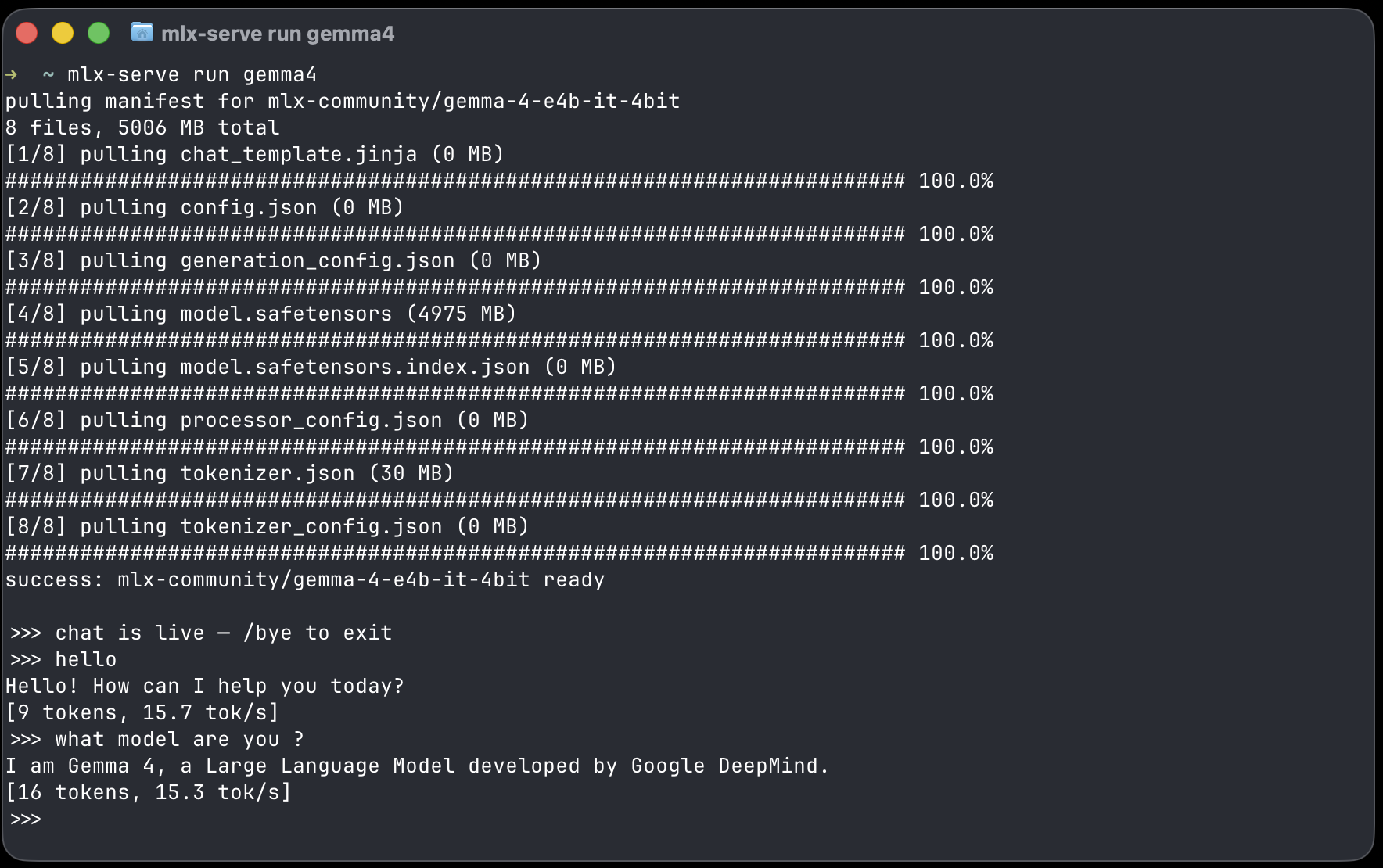
mlx-serve run gemma4 — pull, serve, and chat with live tok/s, Ollama-style.