Models
Two engines, one click each
Pick your model in the Image pane, hit Download once, and generate with a live progress bar as it denoises. Both pipelines were validated numerically faithful to their references.
Fast
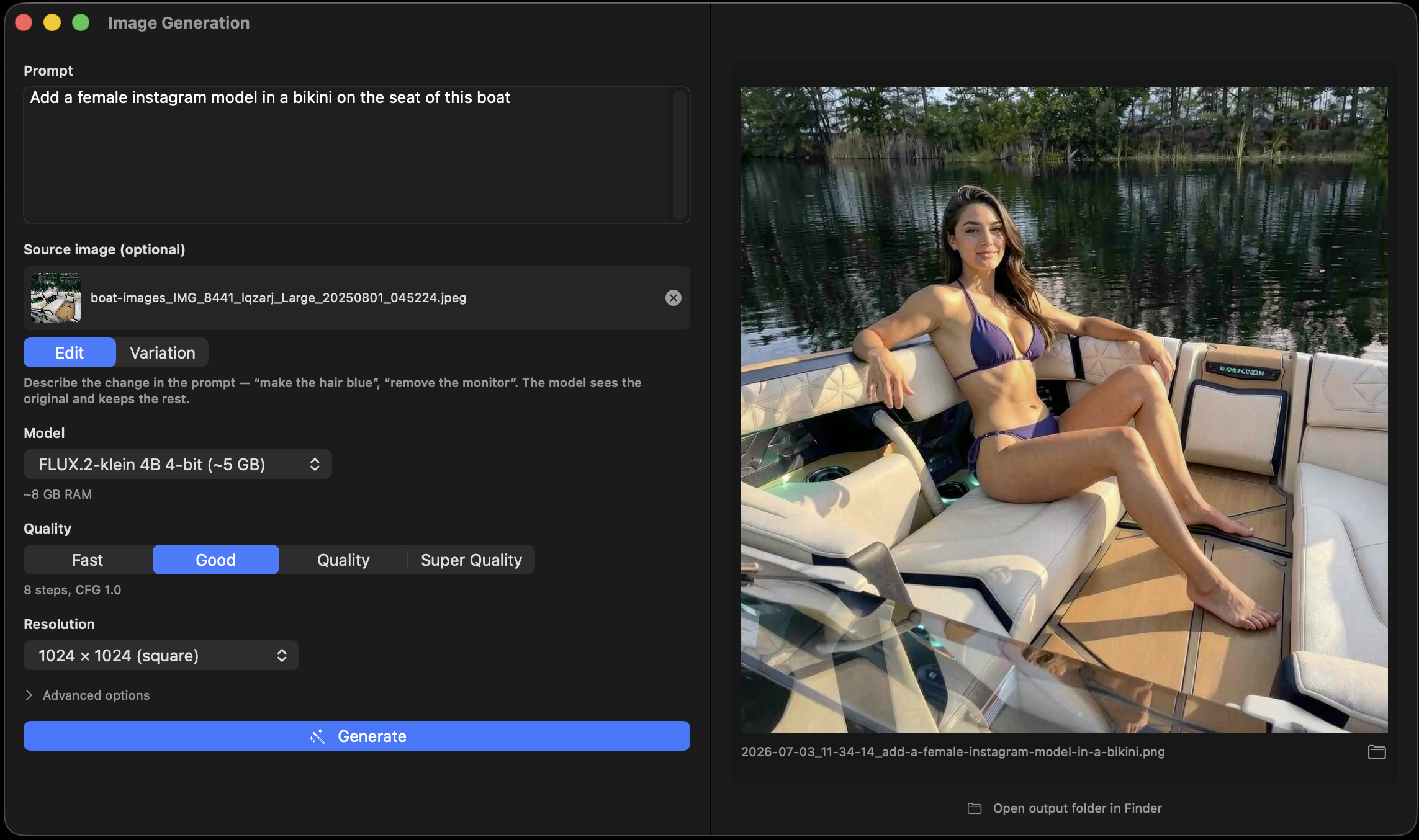
FLUX.2-klein
4B parameters, ~5 GB pre-quantized. Quick results, and the engine behind instruction photo editing. Comfortable on 8–16 GB Macs.
Photorealistic
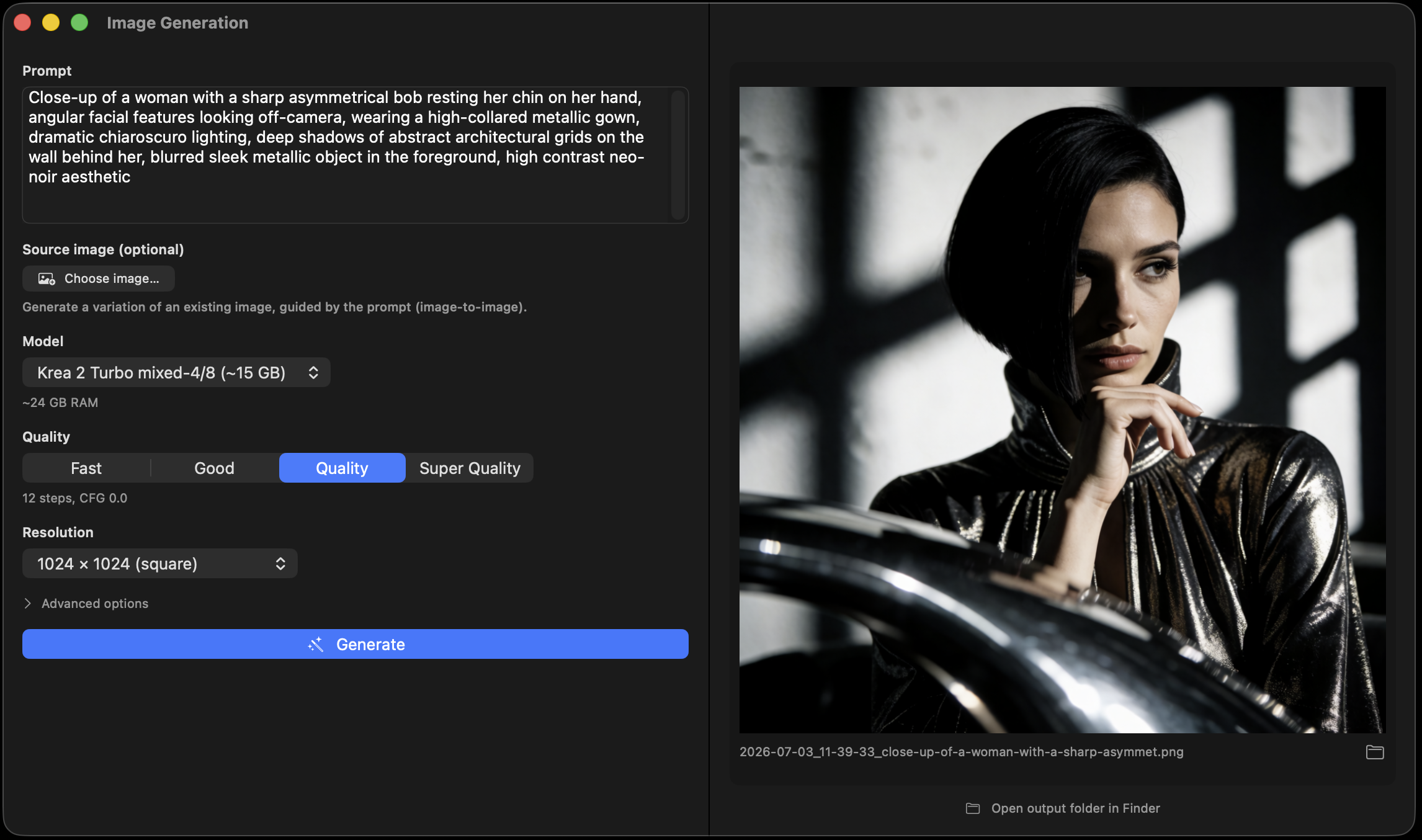
Krea-2-Turbo
12.9B parameters, one-click ~15 GB download. Photorealism validated at 0.9996 end-to-end pixel cosine against the reference implementation.
Safety
On-device screening
Every generated image passes a local NSFW classifier — nothing is uploaded anywhere. On by default, with a Safe-mode toggle (and a --no-safety flag).
In chat
Ask the agent for an image
In Agent mode, "draw a red fox in the snow" renders inline in the conversation with your saved Image settings. Double-click to open full-size.