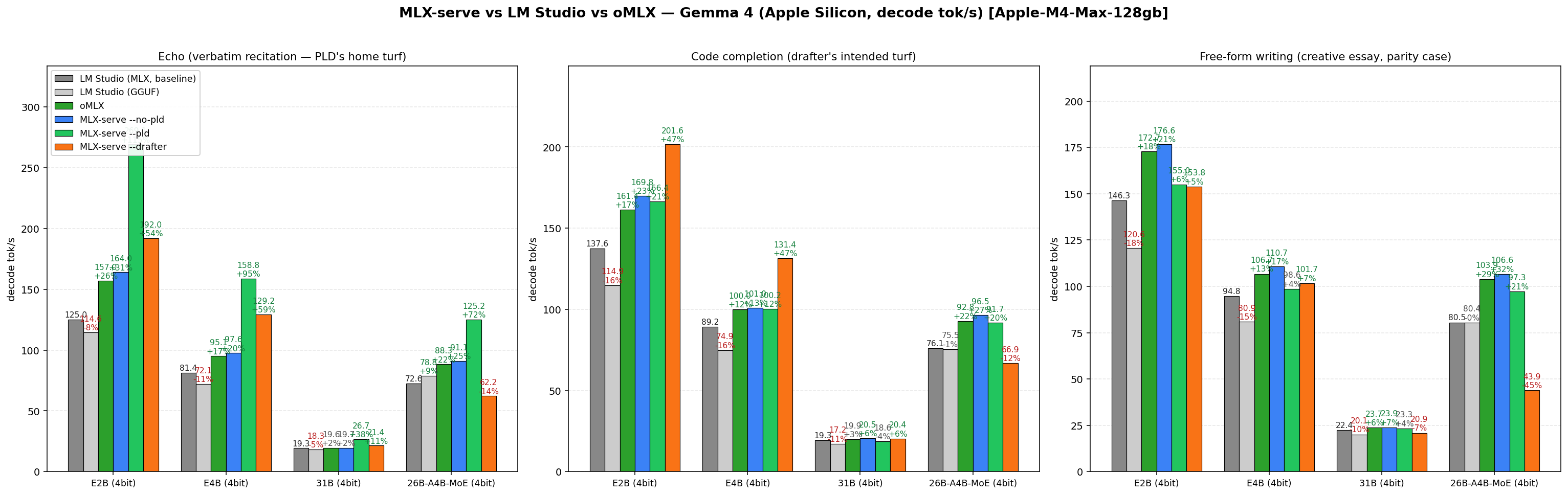
Measured
Where the speed lands
Apple M-series, 4-bit MLX weights, temp 0. Reproduce with tests/bench.sh — the harness ships in the repo.
2.65×
echo workloads · Gemma 4 E4B + PLD
1.61×
agentic code edits · Gemma 4 E4B
1.8×
agent edit loops · Qwen 3.6 native MTP
1.0×
creative writing — gated, no regression