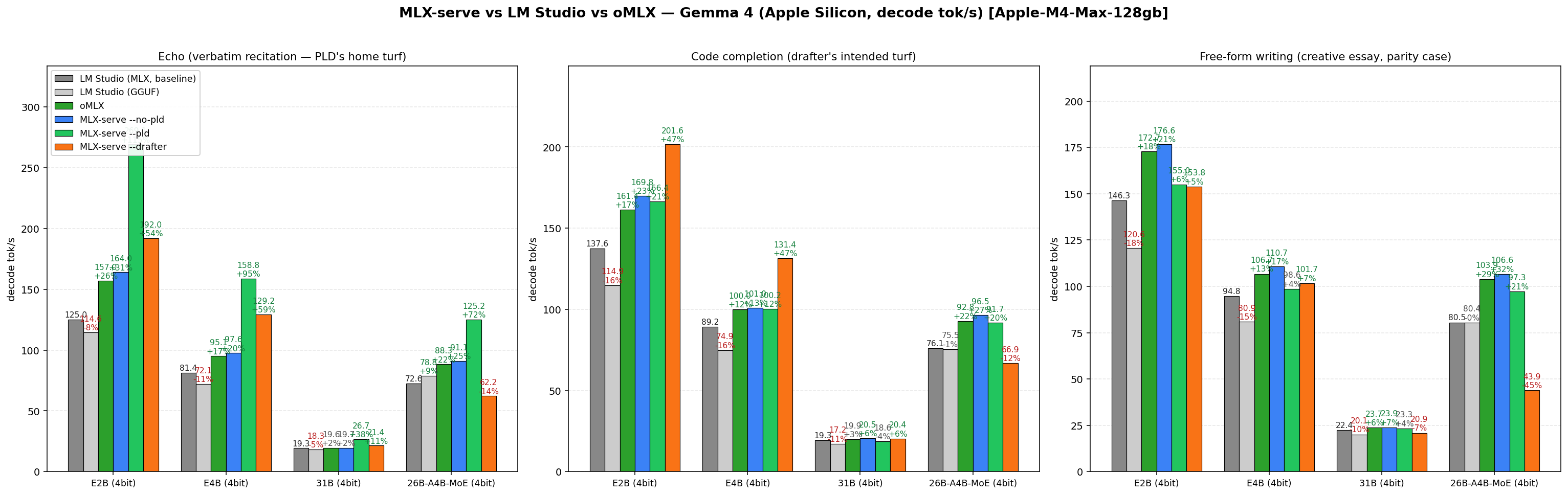
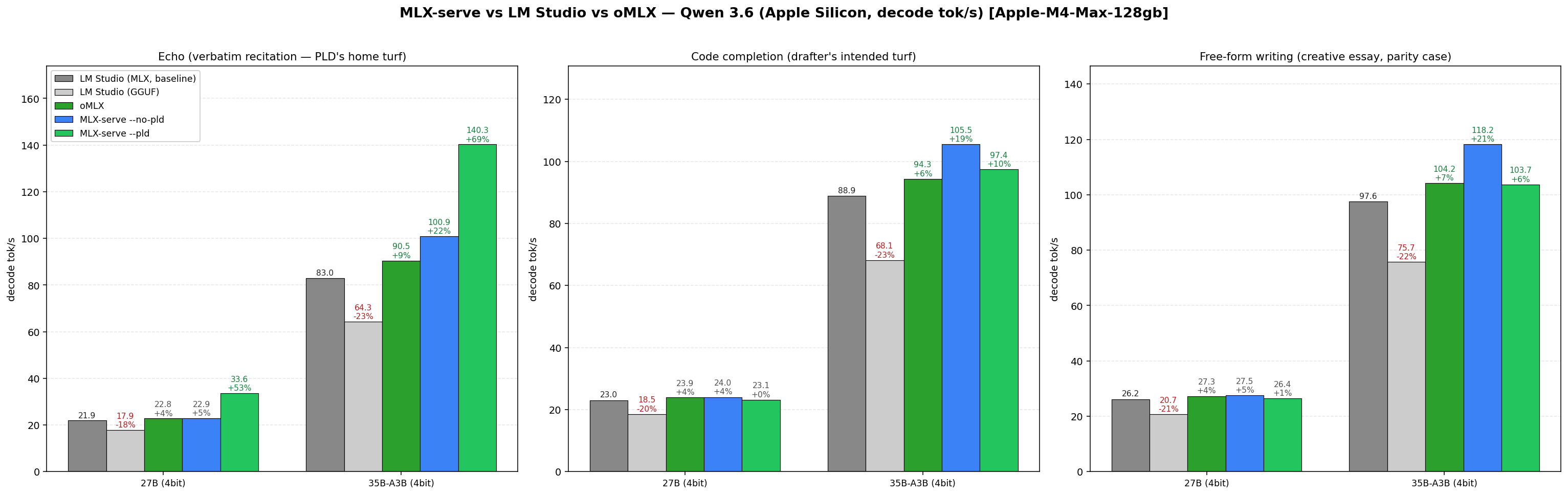
Is mlx-serve really faster than LM Studio?
Yes — every cell, every model we've benchmarked. +35% geomean across 18 workloads on identical 4-bit MLX weights (Gemma 4 E2B/E4B/31B/26B-A4B-MoE, Qwen 3.6 27B/35B-A3B-MoE), and +12–15% decode on the very same .gguf file. The benchmark harness ships in the repo so you can reproduce it on your own machine.
Do I have to re-download my models?
No. MLX Core auto-discovers LM Studio's model folder via ~/.lmstudio/settings.json — everything on disk appears in the picker. A custom-folder picker covers models stored anywhere else.
What does it add beyond speed?
An Anthropic Messages API (Claude Code works natively), the OpenAI Responses API + WebSockets, a drop-in Ollama API, agent mode with MCP, an isolated Linux VM for agent shell commands, speculative decoding, KV-cache quantization, continuous batching, DeepSeek V4 Flash, and fully local image, video, and voice generation.
Is it open source?
Yes — MIT license, server and app both. LM Studio is proprietary freeware; mlx-serve you can read, fork, and ship.