Three ways in
Prompt, photo, or soundtrack
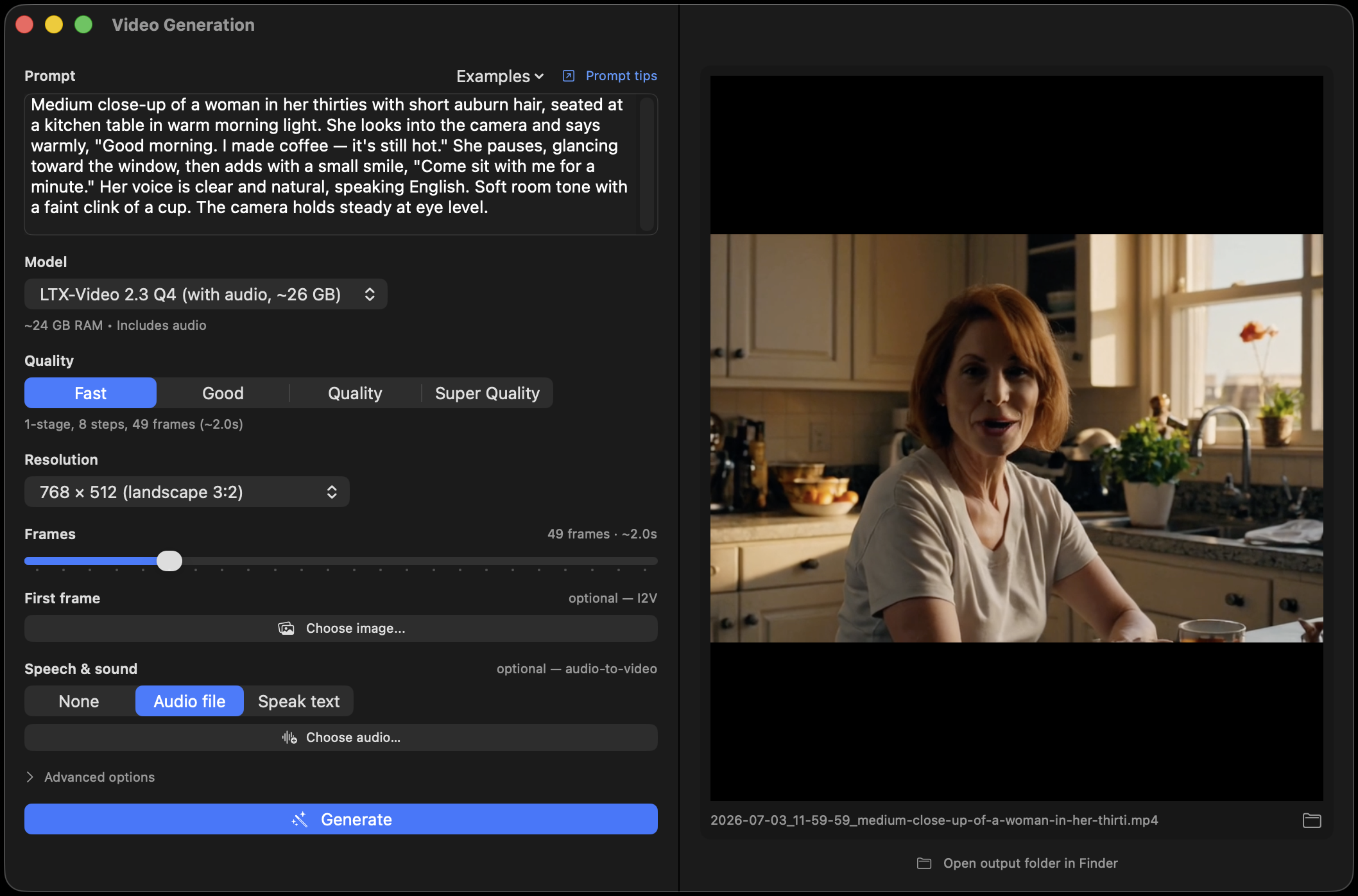
Text → video
Describe the shot
Type a prompt, pick a quality preset, get a clip with synchronized audio. The one-stage path runs guidance-free by default — ~2× faster per step with a more natural look.
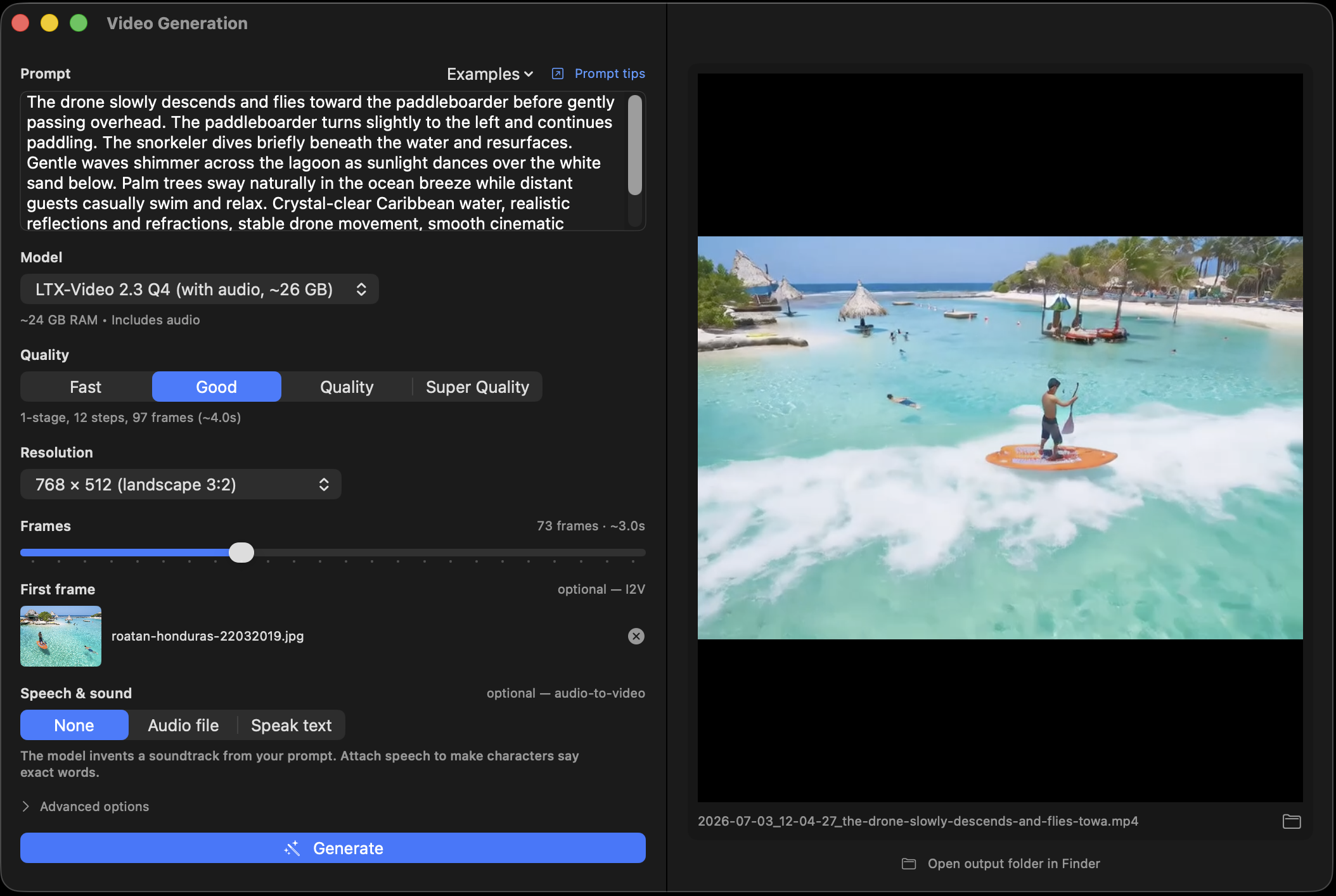
Photo → video
Animate your own picture
Drop an image into the First-frame slot and the clip begins exactly from it — VAE-encoded on-device and locked as the clean opening frame, then animated forward.
Audio → video
Perform to a soundtrack
Attach speech or music, and the video is generated against that clip — timing, performance, and lip sync follow the audio, and the original recording lands in the mp4, not a re-synthesis.